The talk describes what challenges HERE faces in processing Data Subject Requests, e.g. data deletion requests, and how we automated this process to scale it to process up to thousands of requests per week. The talk introduces an experimental approach that uses LLMs to automated extraction of relevant information from free-text emails.
Category: Uncategorized
Keynote at IWPE 2024 on Context-Aware Detection of Personal Data with LLMs
I presented an invited Keynote at the 2024 International Workshop on Privacy Engineering.
The talk describes a collaboration with Elena Vidyakina and Zihong Pi on finetuning an LLM model to classify personal and business names, e.g. the business owner’s name being mistakenly reported as the business’ name. This classification is especially tricky as it heavily depends on context, which might not be available during analysis, e.g. ”Baker” could refer to a surname or a profession.
Talk at PEPR 2024 on Automating Technical Privacy Reviews Using LLMs
I presented a peer-reviewed talk, together with Engin Bozdag, at the 2024 USENIX Conference on Privacy Engineering Practice and Respect.
The talk explored how Uber and Here Technologies have worked to improve efficiency of their review triage processes via automation. Large Language Models (LLMs) are suited to assess the completeness of technical documentation and classify a feature/project into high or low risk buckets, due to the textual representation of information and the models being trained on privacy and security concepts.
Interview on the Shifting Pivacy Left Podcast
I had the honour to speak on the Shifting Privacy Left Podcast, about what it means to be a privacy engineer and other privacy topics.
Modelling imperfect knowledge via location semantics for realistic privacy risks estimation in trajectory data
A new paper appeared on Scientific Reports (https://www.nature.com/articles/s41598-021-03762-2).
In this paper, titled “Modelling imperfect knowledge via location semantics for realistic privacy risks estimation in trajectory data” we propose a privacy risk estimation framework that builds on the semantic context associated to location data. By moving away from the assumption that adversaries have perfect knowledge, we can obtain realistic risk estimates and optimize the trade-off between privacy and utility.
My work earned a Honorable Mention in the First-Ever FPF Award for Research Data Stewardship
My work on anonymized location-data sharing was awarded a honorable mention in the first-ever Award for Research Data Stewardship by Future of Privacy Forum (FPF). A big thank you to the colleagues of HERE Privacy Services and of the Spatial Data Center of Excellence at HERE, as well as the academic partners, that made this possible.
My work was part of a collaboration with researchers at Aeres University of Applied Science and the University of Liverpool, to which we provided anonymized mobility data from millions of vehicles to facilitate research on commuter behavior and movement in urban environments.
The data that was shared with researchers was not the raw data, but rather a dataset that was derived from the original data with high similarity and similar formatting. Researchers were not provided with direct access to any non-anonymized data throughout the process.
Paper highlighted on Plos Complexity Channel
The paper “How learning can change the course of evolution” has been highlighted on Plos Complexity Channel
PhD Thesis: Machine learning for autonomous privacy preservation in participatory sensing and smart cities
Available at https://doi.org/10.3929/ethz-b-000302965
Volunteers in the Smart City: Comparison of Contribution Strategies on Human-Centered Measures
Provision of smart city services often relies on users contribution, e.g., of data, which can be costly for the users in terms of privacy. Privacy risks, as well as unfair distribution of benefits to the users, should be minimized as they undermine user participation, which is crucial for the success of smart city applications. This paper investigates privacy, fairness, and social welfare in smart city applications by means of computer simulations grounded on real-world data, i.e., smart meter readings and participatory sensing. We generalize the use of public good theory as a model for resource management in smart city applications, by proposing a design principle that is applicable across application scenarios, where provision of a service depends on user contributions. We verify its applicability by showing its implementation in two scenarios: smart grid and traffic congestion information system. Following this design principle, we evaluate different classes of algorithms for resource management, with respect to human-centered measures, i.e., privacy, fairness and social welfare, and identify algorithm-specific trade-offs that are scenario independent. These results could be of interest to smart city application designers to choose a suitable algorithm given a scenario-specific set of requirements, and to users to choose a service based on an algorithm that matches their privacy preferences.
Keywords: Participatory sensing; smart cities; public good; privacy; fairness
How intelligence can change the course of evolution.
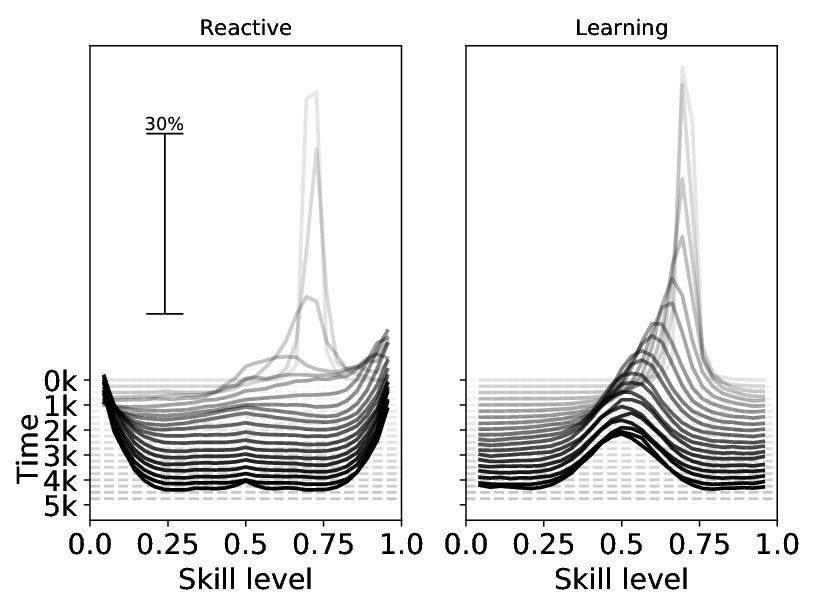
The question of whether learning has an effect on the evolutionary process sparked plenty of research in the fields of Biology and Machine Learning. After more than 100 years of discussion, the consensus is that learning influences the speed of evolutionary convergence to a specific genetic configuration.
Our work looks at the same question in dynamic environments where the optimal behavior changes cyclically between different configurations, thus agents never stop adapting.
We find that in this situation evolution alone favors agents that specialize to a specific configuration, while the combination of evolution and learning prevents specialized strategies to evolve. This result demonstrates that learning does not only influence the speed but also the outcome of evolution.
This work is relevant for the fields of Biology and Machine Learning, as it demonstrates a new effect that we hope will start a new thread of research.
Furthermore, our results might extend to other cyclically-changing contexts in other fields, for example opinion formation and polarization.
Keywords: Baldwin effect, Foraging, Specialist, Generalist, Environmental variability, Evolution, Agent-based modeling, Learning, Neural network, Reinforcement learning